東京大学松尾・岩澤研究室
日本全体の開発レベル向上を志し、
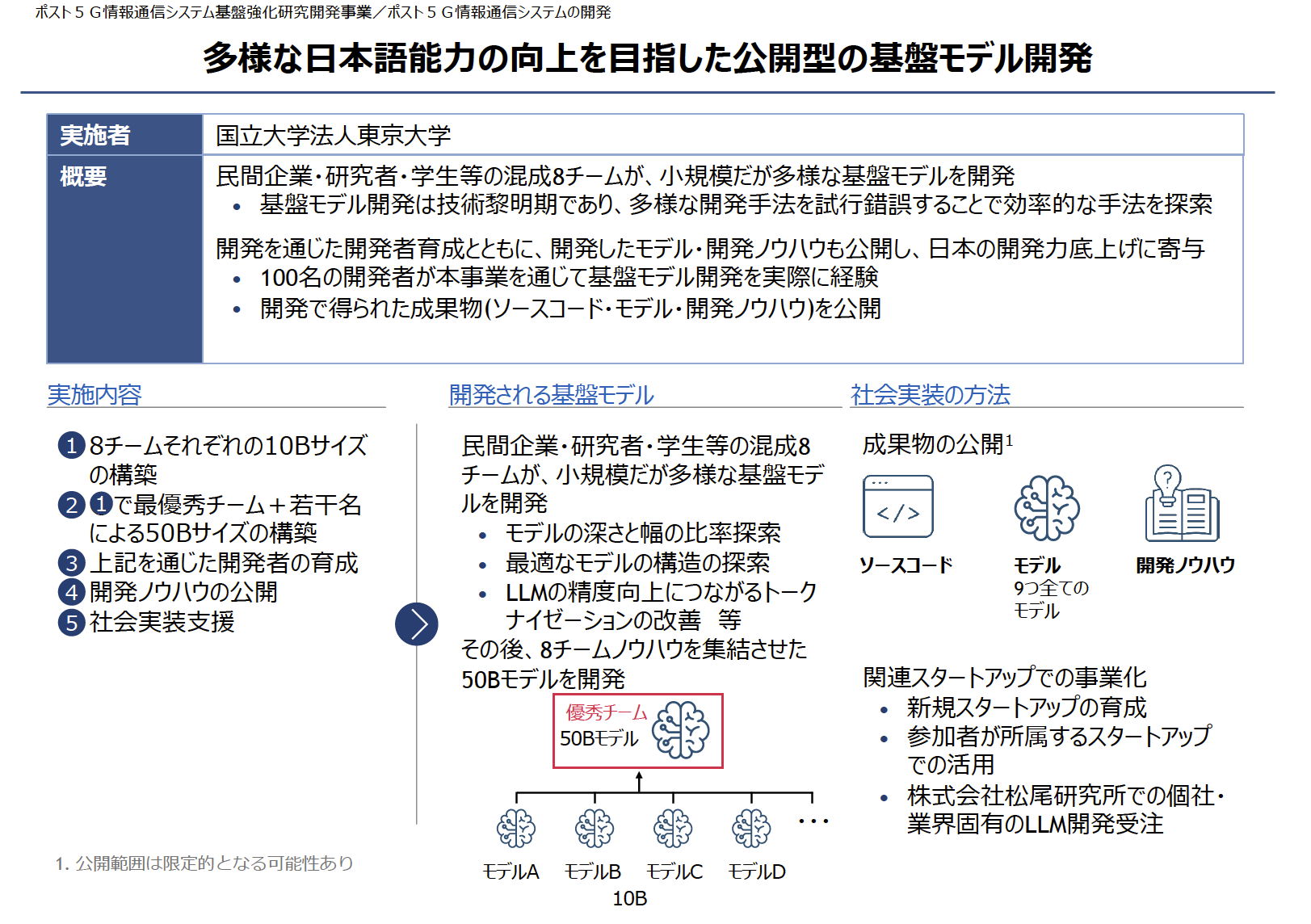
公開型での500億パラメータサイズの大規模言語モデル開発を開始
―NEDO「ポスト5G情報通信システム基盤強化研究開発事業」事業(注1)採択事業者に決定―
東京大学大学院工学系研究科技術経営戦略学専攻 松尾・岩澤研究室(以下「松尾研」)は、この度経済産業省及び国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)が開始する、国内の生成AIの開発力を強化するためのプロジェクト「GENIAC(Generative AI Accelerator Challenge)」において、基盤モデル開発に必要な計算資源の提供支援を受け、500億パラメータサイズの公開型基盤モデル開発に取り組むことをお知らせします。
本取り組みにあたっては、開発された大規模言語モデル(以下「LLM」)の公開のみならず、開発過程の公開、そしてこれらの成果を社会全体で共有することを通じ、日本全体のLLM開発の技術レベル向上と社会実装の加速を目指します。
発表の詳細
本活動では、2023年8月に公開した100億パラメータサイズのLLM「Weblab-10B」の開発経験をベースに、東京大学松尾研究室が提供する大規模言語モデル講座(2023年8月開催、2000名以上が受講)の修了生及び一般公募によって集まった有志の開発者(⺠間企業・研究者・学⽣で構成)が、最新の研究成果や技術的な知見を取り入れ、開発を進めます。
一般的にLLMの最適なモデル構造やハイパーパラメータは十分に分かっていないため、第1フェーズにおいては8チームに分かれて複数の研究テーマを設定し探索を行い、知見を共有しながら試行錯誤することで、実用的かつ効率的な手法を採用します。その後第2フェーズでは、最優秀に選ばれた1チームが500億パラメータサイズのLLM開発に取り組むことを予定しています。なお、本活動は、基盤モデルの開発評価の過程でWeights & Biases社のプラットフォームを活用した開発を進めていきます。
松尾研では本活動に参加を希望される有志の開発者を募集しております。募集要項は下記ページをご確認ください。
https://weblab.t.u-tokyo.ac.jp/geniac_llm
本活動を通じて開発されたモデル・ソースコード・開発過程・ノウハウは、2024年4月以降、松尾研のホームページ等を通じ広く公開してまいります。これらの透明性の高いアプローチを通じ、社会全体の技術リテラシーの向上と産業界やアカデミアにおける応用を促進して参ります。
注釈
(注1)国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)「ポスト5G情報通信システム基盤強化研究開発事業/ポスト5G情報通信システムの開発」事業。経済産業省が主導する基盤モデルの開発に必要な計算資源に関する支援や関係者間の連携を促す「GENIAC」プロジェクトの一環として採択事業者に一定の計算資源に関わる助成を行うもの。
GENIACの詳細はこちら:
https://www.meti.go.jp/press/2023/02/20240202003/20240202003.html
https://weblab.t.u-tokyo.ac.jp/geniac_llm
本件に関する問合せ先
東京大学 大学院工学系研究科 松尾・岩澤研究室
E-mail:pr@weblab.t.u-tokyo.ac.jp

 日本語
日本語
