
 日本語
日本語
Sorry, this entry is only available in Japanese. For the sake of viewer convenience, the content is shown below in the alternative language. You may click the link to switch the active language.
国際人工知能会議(IJCAI2020)にて、このほど当研究室の論文
「Stabilizing Adversarial Invariance Induction from Divergence Minimization Perspective」(分布マッチングの観点からみた敵対的不変表現学習の安定化)
が採択されました。
著者:岩澤有祐、阿久澤圭、松尾豊
論文リンク:https://www.ijcai.org/Proceedings/2020/271
主な著者である松尾研究室 特任助教 岩澤さんより、
論文の概要や採択までのエピソードについて解説してもらいました。
敵対的学習を用いた不変表現学習
今回の研究は、「不変表現学習」についてです。
表現の不変性とは、ある表現が特定の因子に対して独立であることを指す概念です。
不変性が重要な例として、監視カメラの動画から不審行動を検知するシステムを考えてみます。このシステムが、もし背丈などの身体的特徴に依存した予測をしていると、身体的特徴によって予測精度が大きくぶれる(ある特定のユーザ群にはうまく働くが,他のユーザ群にはうまく働かない)といった問題を引き起こす可能性があります。実際にシステムを活用する多くの場面では、未知のユーザに対してもうまく働くことが期待されるため、このような予測のぶれを防ぐために身体的特徴に依存しない情報(表現)を活用した判断をする必要があります。
あるいは、たとえば肌が黒い人がいるという情報を抽出し、それを判断の基準に利用することは、社会通念上問題になる場合があります。公平性の観点から、検知システムは肌の色に依存しないことが求められます。
しかし、表現学習の手法として近年よく使われる深層ニューラルネットワーク(以下、DNN)は、獲得した表現が、このように特定の因子に対し独立である(不変性を持つ)とは限りません。このような制約を、明示的にDNNの学習に組み込む技術が、「不変表現学習」と呼ばれる技術です。
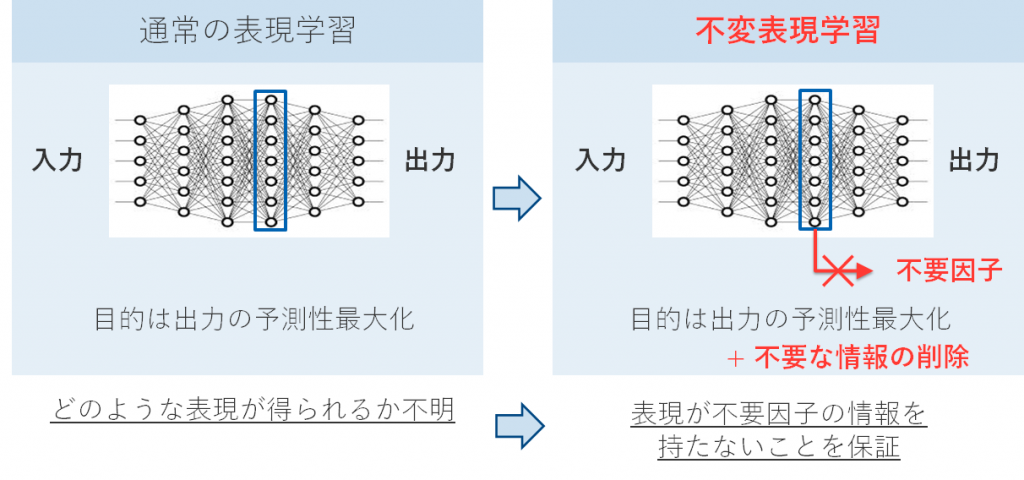
図1 表現学習と不変表現学習の比較。不変表現学習では、予測性の最大化に加えて、不要な因子の情報を持たない表現を学習ことが求められる。
このような既存技術の一つに、敵対的不変表現学習手法(Adversarial Invariance Induction, AII)というものが知られています [Xie+2017]。AIIの肝は、「現在の表現がどのくらい不要な情報を持っているか」もニューラルネットワークによって計測し、学習に利用することです。より具体的には,現在の表現から取り除きたい情報を予測する敵対的な分類器を学習し、その学習器を使っても情報が取り出せない方向(つまり分類器を騙す方向)に学習が進むように制約をかけます。情報を取り出そうとする分類器と、それを防ごうとする表現学習器が戦い合うような構造をしているため、敵対的な学習と呼ばれています。
参考:[Xie+2017] Controllable Invariance through Adversarial Feature Learning
AIIは妥当な不変性の尺度である条件付エントロピーと密接な関係にあるなど理論的に優れている点が知られており、さまざまな拡張手法も提案されています。
しかし、AIIの挙動は不安定であることが報告されています。図2において、緑線は理論上最適な不変性、赤線が実際の不変性、青線がAIIが学習に利用している推定値を表していますが、推定値が実際の不変性と大きく離れてしまっており、また推定値も乱高下しています。
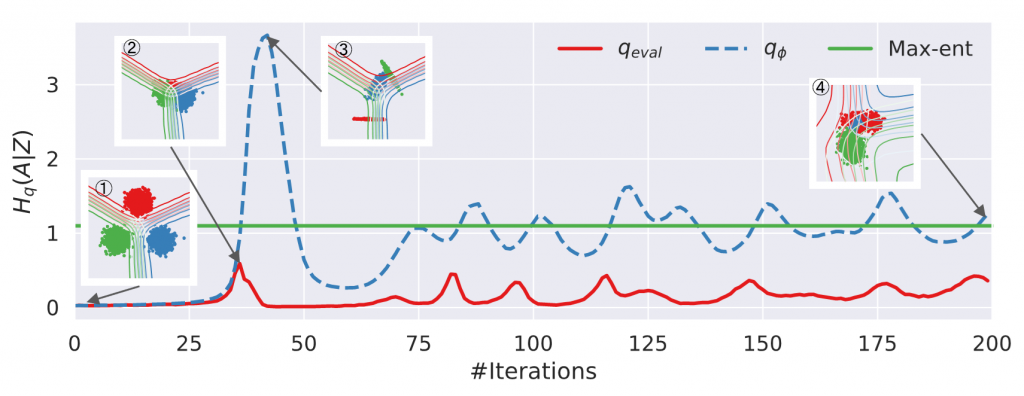
図2 トイデータを用いたAIIの不安定な挙動の可視化
では、このような問題はなぜ発生し、どのように解消できるのでしょうか?
分布マッチングの観点からみた敵対的特徴学習の安定化
本研究では、この問題について分布マッチングの観点からみた提案をしました。ここでいう分布マッチングとは、ある属性に関する特徴表現の分布を、別の属性に関する分布に近づけるような処理のことです。
残念なことに、このような分布マッチングの観点はAIIが最適化している目的関数(あるいはその勾配)には現れません。図3(中央)に、先ほど述べたトイデータにおいてAIIの学習規則によって得られる勾配ベクトル(属性1=赤点のデータ分布が学習によってどのように移動するか)、およびその勾配ベクトルを計算するために使われる要素を可視化したものを示しました。
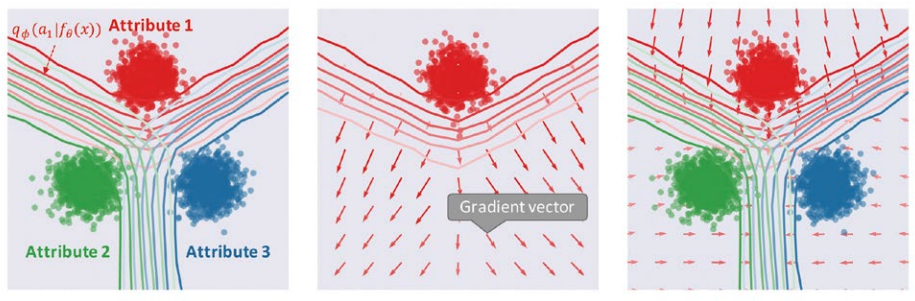
図3 AII(中央)と提案法(右)の敵対的学習における勾配ベクトルの比較。両手法とも特徴空間上での属性分類器(左図等高線)を騙すことで不変性を獲得するが、騙し方が異なる
このように、AIIは、データ分布を更新する際に別の属性のデータ分布がどこにあるかという情報をまったく利用しない(厳密には、分類境界を介して間接的にしか利用しない)ため、「分布マッチングするかにかかわらず決定境界から離れるほど良い」 という学習規則になっています。
本研究では、上記の「分布マッチングの欠如」がAIIの不安定性を引き起こしているという仮説の下、AIIの枠組みを分布マッチングを考慮するように変更した手法を提案しました。特徴表現から因子を予測する分類器(分類するための機械学習モデル)を学習中に利用し、この分類器を騙すことで、不変性を達成するように学習します。
実験では、既存手法が学習に失敗するようなトイデータで提案法が一貫して最適に近い不変性を達成できることを示しました。また実際的な応用例として、分布シフトに対する分類器のロバスト性(外部の影響を排除したり、最小限に抑えたりする能力)の改善、ウェアラブルセンシングにおけるプライバシー保護に利用できることを示しました。詳しくは、元論文をご参照いただければと思います。
松尾研における本論文の意義と、今後の展望
今回の研究では主に工学的な応用の側面に着目していますが、松尾研が進めている「世界モデル」(※)との関係でいうと、本研究の内容は反実仮想を生成する、目の前にはない状況を作り出すような基礎技術として位置づけられると思います。
このような技術は、たとえば、ある行動を起こしたときに何が起こるかを適切に「想像」してより良い行動選択につなげる、あるいは言語的な情報をもとに目の前にはない状態をシミュレートして学習につなげる、といった、効率的な学習技術の大きな発展につながると考えています。
※参考:日経クロストレンド 東大松尾ゼミの「深層学習」研究会 第4回「世界モデル~世界の構造を理解して予測・想像するAI~」
「ある因子に対して表現が不変になるように制約する」こと自体は、予測精度を上げる、あるいは社会的な制約を考慮するなど、工学的な応用における幅広い場面で重要になり得る技術だと思っています。松尾研では多様な応用研究が推進されていますが、さまざまな領域で類似した手法が活用していければと思っています。
また私自身、前述のような反実仮想の生成といった、より基礎的な問題に対して、本研究での知見を生かしていきたいと思います。
あとがき
研究の内容とは異なる観点ですが、実は今回の研究は初期の構想自体は2年ほど前で,何度か再投稿を繰り返しました。その間、「実験が弱い」、「手法を導き出す方法が分かりにくい」等、さまざまなフィードバックを受けました。「この論文は通すべきではない(以上)」といったコメントを受けたこともありました。
その間にもちろん細かい追加実験や記述の修正はしたものの、大筋の内容は大きく変更していません。
当たり前のことですが、科学というのは積み重ねなので、「面白いけど粗がある」「実験結果は良いけど、なぜかよくわからない(信頼性に欠ける)」というものを採択することはできません。振り返ってみると、初期の原稿はこのような読み手からみたときの感覚に十分に答えられてなかったように思います。
採択されるかどうかの最終的な差になるのは、(もちろん研究成果が一定以上あるのは当然として)対象となるコミュニティとどれだけ意識を一致させられているか、どれだけ読者のことをリアルにイメージできているか、そして読者が持つ疑問に答えられているかという点だと感じています(最初にも書いたとおり当たり前のことではありますし、それができれば苦労しないのですが…)。
一言でいうと「完成度を上げる」ということですが、その背景にある重要な観点は、コミュニティとの意識の一致だと、今回の件を通して改めて思いました。
 【プロフィール】
【プロフィール】
岩澤有祐(いわさわ・ゆうすけ)
2012年に上智大学(情報理工学科、矢入研究室)を卒業。2014年に上智大学大学院 博士前期課程(情報学領域、矢入研究室)を修了。2017年に東京大学大学院 博士後期課程(技術経営戦略学専攻、松尾研究室)を修了。2018年より東京大学松尾研究室にて特任助教(現職)。博士(工学)。専門は深層学習、特にウェアラブルセンシングへの応用と、知識転移に関する技術。
論文については以下よりご覧ください。
【タイトル】
Stabilizing Adversarial Invariance Induction from Divergence Minimization Perspective
【概要】
Adversarial invariance induction (AII) is a generic and powerful framework for enforcing an invariance to nuisance attributes into neural network representations. However, its optimization is often unstable and little is known about its practical behavior. This paper presents an analysis of the reasons for the optimization difficulties and provides a better optimization procedure by rethinking AII from a divergence minimization perspective. Interestingly, this perspective indicates a cause of the optimization difficulties: it does not ensure proper divergence minimization, which is a requirement of the invariant representations. We then propose a simple variant of AII, called invariance induction by discriminator matching, which takes into account the divergence minimization interpretation of the invariant representations. Our method consistently achieves near-optimal invariance in toy datasets with various configurations in which the original AII is catastrophically unstable. Extensive experiments on four real-world datasets also support the superior performance of the proposed method, leading to improved user anonymization and domain generalization.
【著者】岩澤有祐,阿久澤圭,松尾豊
【論文リンク】https://www.ijcai.org/Proceedings/2020/271
論文の概要は新学術領域研究「人工知能と脳科学の対照と融合」ニュースレーターVol.8 (2020年10月)P.14でも日本語で紹介しています。


