
*At Matsuo Lab, about 10 researchers are working on research in the area of artificial intelligence on a daily basis.
We would like to provide young researchers and students with an opportunity to learn about the results of our research,
We will provide the contents of our papers in an easy-to-understand manner on this Lab News page.
Our laboratory’s paper was recently presented at the International Conference on Artificial Intelligence (IJCAI2020).
Stabilizing Adversarial Invariance Induction from a Divergence Minimization Perspective” (Stabilizing Adversarial Invariant Representation Learning from a Distribution Matching Perspective)
was adopted.
Authors: Yusuke Iwasawa, Kei Akuzawa, Yutaka Matsuo
Paper link: https://www.ijcai.org/Proceedings/2020/271
From the lead author, Dr. Iwasawa, Project Assistant Professor in Matsuo Laboratory,
Mr. Iwasawa, Project Assistant Professor in Matsuo Laboratory, gave an overview of the paper and the episodes leading up to its adoption.
Invariant Representation Learning with Adversarial Learning
This study is about “invariant representation learning”.
Representation invariance is a concept that refers to the fact that a representation is independent of a particular factor.
As an example where invariance is important, consider a system that detects suspicious behavior from surveillance video. If this system relies on physical characteristics such as height to make predictions, it could cause problems such as large swings in prediction accuracy depending on physical characteristics (i.e., the system works well for a certain group of users but not for others). In many situations where the system is actually used, it is expected to work well for unknown users, so it is necessary to make decisions using information (expressions) that do not depend on physical characteristics in order to prevent this kind of blurring of predictions.
Or, for example, extracting information that someone has dark skin and using it as a criterion for judgment may be problematic from a socially accepted perspective. From the standpoint of fairness, the detection system must be independent of skin color.
However, deep neural networks (hereafter referred to as DNNs), which have been used frequently in recent years as a representation learning technique, do not necessarily ensure that the acquired representations are independent (invariant) to a specific factor in this way. A technique that explicitly incorporates such constraints into the learning of DNNs is called “invariant representation learning.
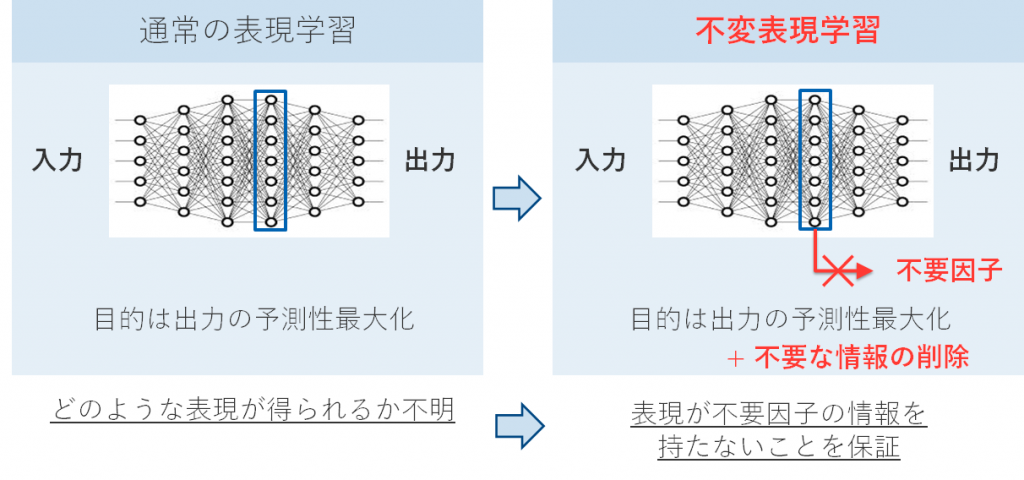
Figure 1 Comparison of representation learning and invariant representation learning. In invariant representation learning, in addition to maximizing predictability, it is required to learn a representation that has no information on unnecessary factors.
One such existing technique is known as Adversarial Invariance Induction (AII) [Xie+2017]. the crux of AII is that “how much unnecessary information the current representation has” is also measured by the neural network by means of a neural network and use it for learning. More specifically, it learns a hostile classifier that predicts the information it wants to remove from the current representation, and constrains the learning to proceed in the direction where information cannot be extracted using that classifier (i.e., in the direction that tricks the classifier). It is called adversarial learning because the structure is such that the classifier that tries to extract information and the representation learner that tries to prevent it fight each other.
Reference: [Xie+2017] Controllable Invariance through Adversarial Feature Learning
AII is known for its theoretical advantages, such as its close relationship to conditional entropy, a reasonable measure of invariance, and various extension methods have been proposed.
However, the behavior of AII has been reported to be unstable. In Figure 2, the green line represents the theoretically optimal invariance, the red line the actual invariance, and the blue line the estimate that AII uses for learning.
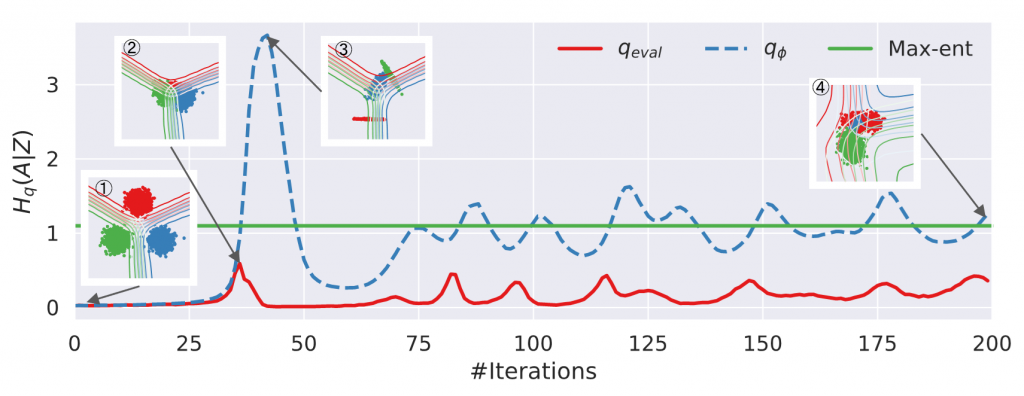
Figure 2 Visualization of unstable behavior of AII using toy data
So why do these problems occur and how can they be resolved?
Stabilization of adversarial feature learning from a distribution matching perspective
In this study, we proposed to look at this problem from the perspective of distribution matching. Distribution matching here refers to a process that brings the distribution of feature expressions for one attribute closer to the distribution for another attribute.
Unfortunately, this distribution matching perspective does not appear in the objective function (or its gradient) that AII optimizes. Figure 3 (center) shows a visualization of the gradient vector obtained by AII’s learning rule in the toy data just described (how the data distribution of attribute 1 = red points shifts with learning), and the elements used to compute that gradient vector.
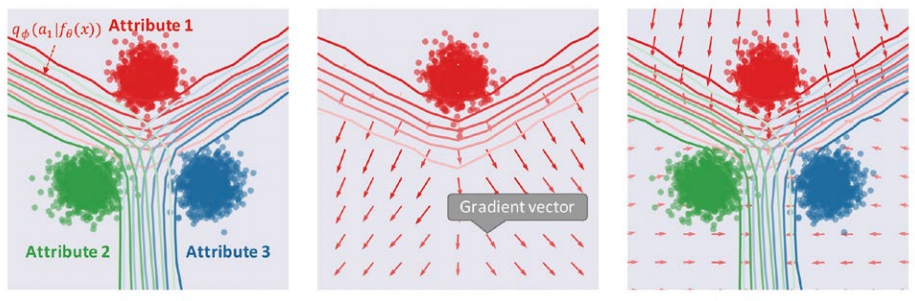
Figure 3 Comparison of gradient vectors in adversarial learning between AII (center) and the proposed method (right). Both methods acquire invariance by tricking the attribute classifier (contour lines on the left) on the feature space, but the tricking method is different
Thus, AII does not use any information about where another attribute’s data distribution is located when updating the data distribution (strictly speaking, it uses it only indirectly via the classification boundary), and the learning rule is “the further away from the decision boundary the better” regardless of whether the distribution matching.
Based on the hypothesis that the above “lack of distribution matching” is causing the instability of AII, we proposed a method in which the AII framework is modified to take distribution matching into account. A classifier (a machine learning model to classify) that predicts factors from feature representations is utilized during training, and this classifier is tricked to learn to achieve invariance.
Experiments showed that the proposed method can consistently achieve near-optimal invariance on toy data where existing methods fail to learn. As practical applications, we also showed that the proposed method can be used to improve the robustness (ability to eliminate or minimize external influences) of classifiers to distribution shifts and to protect privacy in wearable sensing. For more information, please refer to the original paper.
Significance of this paper for the Matsuo Institute and future prospects
Although this research mainly focuses on the engineering application aspect, in relation to the “world model” (*) that the Matsuo Lab is working on, the content of this research can be positioned as a basic technology that generates counterfactual virtuality, creating a situation that is not in front of us.
We believe that such technology will lead to major advances in efficient learning techniques, such as, for example, appropriately “imagining” what will happen when a certain action is taken, leading to better action choices, or simulating a situation that is not in front of us based on linguistic information, leading to learning.
*Reference: JSAI2020 OS-18 World Model and Intelligence
I believe that “constraining the expression to be invariant to a factor” itself is a technique that can be important in a wide range of engineering applications, such as improving prediction accuracy or taking social constraints into account. Matsuo Lab is promoting a variety of applied research, and I hope that similar techniques can be used in various fields.
I myself would also like to apply the findings of this study to more fundamental problems, such as the generation of counterfactuals, as mentioned above.
postscript
Although from a different perspective than the content of the study, the initial conception of this study itself was actually about two years ago, and it was resubmitted several times. During that time, we received various feedbacks such as “the experiment is weak,” “it is difficult to understand how to derive the methodology,” etc. I even received comments such as, “This paper should not be passed (or more).”
During that time, of course, we have made minor additional experiments and revisions to the description, but the main content has not changed significantly.
As a matter of course, science is a cumulative process, so we cannot adopt manuscripts that are “interesting but have rough edges” or “experimental results are good, but we are not sure why (they lack credibility). In retrospect, I think that my early manuscripts did not adequately respond to this kind of feeling from the reader’s point of view.
I feel that what ultimately makes the difference between acceptance and rejection is how well you are in tune with your target community (of course, it is a given that your research results are above a certain level), how realistic you are about your readers, and how well you answer their questions (as I mentioned in the beginning, I am not sure how much I can answer these questions). (As I mentioned at the beginning, this is a matter of course, and if we could do that, we would have no trouble…).
In a nutshell, it is about “raising the level of perfection,” but I was reminded through this case that the important perspective behind this is the unity of awareness with the community.

[Profile.
Yusuke Iwasawa
Graduated from Sophia University (Department of Information Science and Technology, Yairi Laboratory) in 2012 Completed the Master’s program in Information Science, Yairi Laboratory, Sophia University in 2014 Completed the Doctoral program in Technology Management Strategy, Matsuo Laboratory, University of Tokyo in 2017 Completed the Doctoral program in Technology Management Strategy, Matsuo Laboratory, University of Tokyo in 2018 University of Tokyo (Matsuo Laboratory) from 2018. D. in Engineering. He specializes in deep learning, especially its application to wearable sensing and techniques related to knowledge transfer.
Please see below for more information about the paper.
Title.
Stabilizing Adversarial Invariance Induction from Divergence Minimization Perspective
Summary
Adversarial invariance induction (AII) is a generic and powerful framework for enforcing an invariance to nuisance attributes into neural network representations. However, its optimization is often unstable and little is known about its practical behavior. This paper presents an analysis of the reasons for the optimization difficulties and provides a better optimization procedure by rethinking AII from a divergence minimization perspective. Interestingly, this perspective indicates a cause of the optimization difficulties: it does not ensure proper divergence minimization, which is a We then propose a simple variant of AII, called invariance induction by discriminator matching, which Our method consistently achieves near-optimal Our method consistently achieves near-optimal invariance in toy datasets with various configurations in which the original AII is catastrophically unstable. Extensive experiments on four real- world datasets also support the superior performance of the proposed method, leading to improved user anonymization and domain generalization.
Author] Yusuke Iwasawa, Kei Akuzawa, Yutaka Matsuo
[paper link]https://www.ijcai.org/Proceedings/2020/271
An overview of the paper is also introduced in Japanese in the New Academic Area Research “Contrast and Integration of Artificial Intelligence and Brain Science” News Letter Vol. 8 (October 2020), p. 14.
