Our paper has been accepted to the ICLR2019 Workshop (Limited Label Data), ECML PKDD.
[Bibliographic Information].
Kei Akuzawa, Yusuke Iwasawa, Yutaka Matsuo: “Adversarial Invariant Feature Learning with Accuracy Constraint for Domain Generalization”, in Proc. of European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, 2019.
[Abstract].
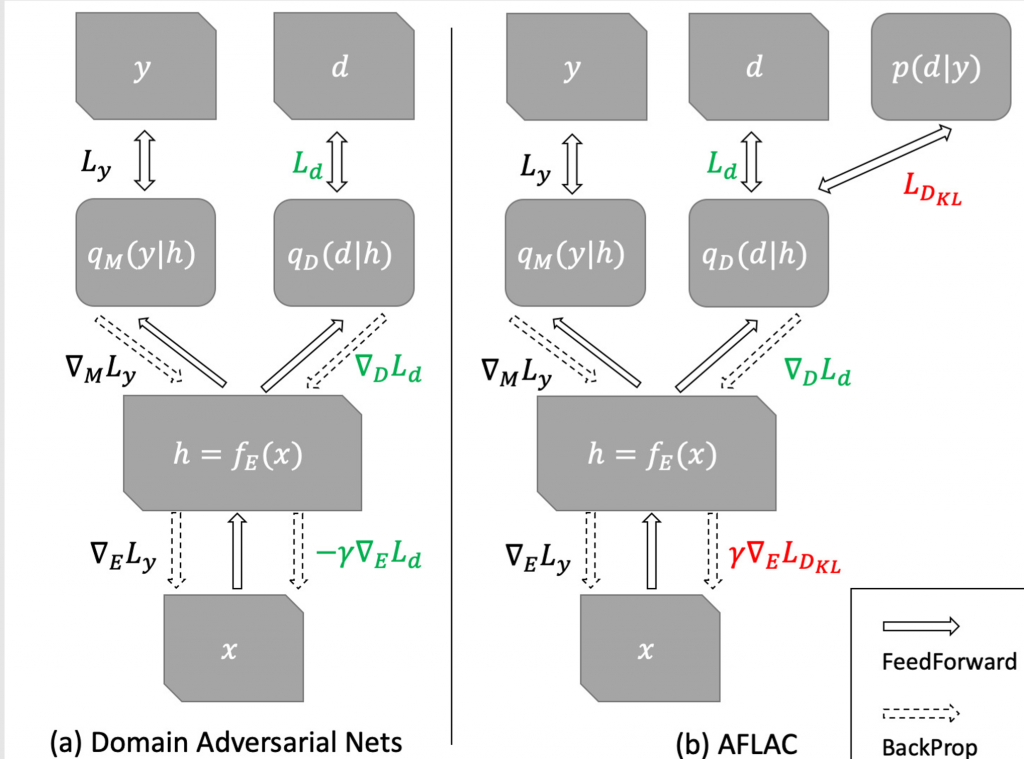
Learning domain-invariant representation is a dominant approach for domain generalization (DG), where we need to build a classifier that is robust toward domain shifts. However, previous domain-invariance-based methods overlooked the underlying dependency of classes on domains, which is However, previous domain-invariance-based methods overlooked the underlying dependency of classes on domains, which is responsible for the trade-off between classification accuracy and domain invariance. Because the primary purpose of DG is to classify unseen domains rather than the invariance itself, the improvement of the invariance can negatively affect DG performance under this trade-off. , this study first expands the analysis of the trade-off by Xie et. al. 2017. and provides the notion of accuracy-constrained domain invariance, which We then propose a novel method adversarial feature learning We then propose a novel method adversarial feature learning with accuracy constraint (AFLAC), which explicitly leads to that invariance on adversarial training. Empirical validations show that the performance of AFLAC is superior to that of domain-invariance-based methods on both synthetic and three real-world datasets, supporting the importance of considering the dependency and the efficacy of the Empirical validations show that the performance of AFLAC is superior to that of domain-invariance-based methods on both synthetic and three real-world datasets, supporting the importance of the dependency and the efficacy of the proposed method.