
Presentation Points
- Matsuo-Iwasawa Laboratory developed and released “Tanuki-8×8B” under the “GENIAC” project promoted by METI and NEDO, which promotes the development of a generative AI infrastructure model in Japan.
- This model was developed from full scratch and achieves the same or better performance as the GPT-3.5 Turbo in the Japanese MT-Bench, an index for evaluating dialogue and writing ability.
- Based on the Apache License 2.0, it can be freely used for research and commercial purposes. A demo of a lightweight version of Tanuki-8B, which can be used in a chat format, is also available.
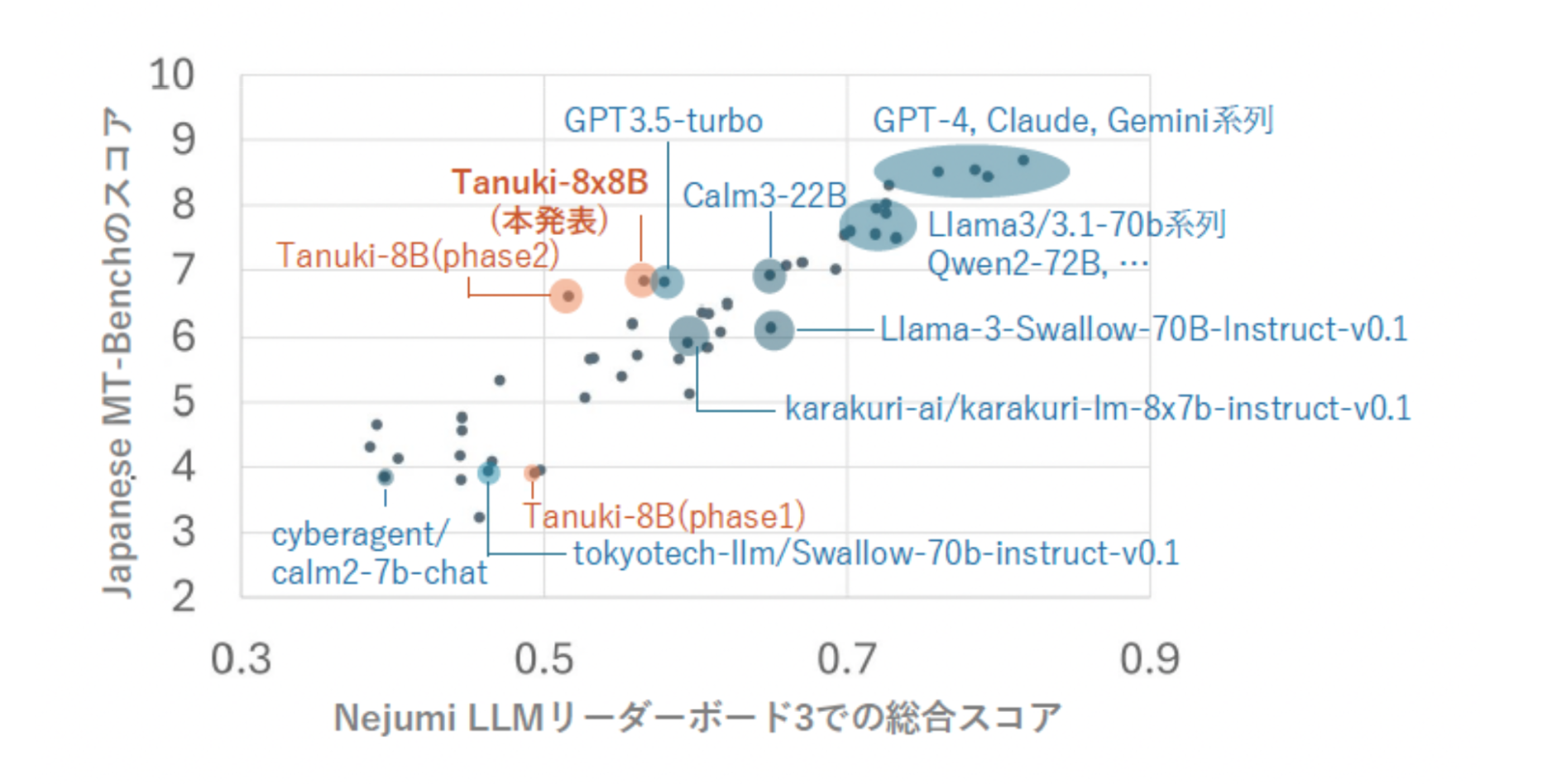
Evaluation ofthis modelon theNejumi LLMLeaderboard3
Announcements
The Matsuo-Iwasawa Laboratory (“Matsuo-Lab”), Department of Technology Management Strategy, Graduate School of Engineering, The University of Tokyo, has developed and released a large-scale language model “Tanuki-8×8B” in the “GENIAC (Generative AI Accelerator Challenge)” (Note 1), a project promoted by the Ministry of Economy, Trade and Industry and the New Energy and Industrial Technology Development Organization (NEDO) to enhance the development capability of generative AI in Japan. Accelerator Challenge (GENIAC) (Note 1), a project promoted by the Ministry of Economy, Trade and Industry (METI) and the New Energy and Industrial Technology Development Organization (NEDO) to strengthen the development capability of generative AI in Japan.
Background of development
This activity builds on the development experience of Weblab-10B, a 10 billion parameter size LLM released in August 2023, in the GENIAC project, which promotes the development of generative AI infrastructure models in Japan.
The development was carried out by students who had completed the Large-Scale Language Modeling Course offered by the Matsuo Institute (held in August 2023, attended by over 2,000 people), as well as by volunteers (consisting of students from private companies, researchers, and students) who gathered from the general public, incorporating their knowledge.
The development process was divided into two phases. In Phase 1 (Note 2), seven teams were divided into a competition-style development process, and in Phase 2, the winning team from Phase 1 took on the challenge of developing an even larger model. Tanuki-8x8B” was developed as a result of this project and is now available to the public.
For more information on the Matsuo Lab GENIAC project, please visit
https://weblab.t.u-tokyo.ac.jp/geniac_llm/
Outline of“Tanuki-8x8B
Tanuki-8×8B” is an efficiently additionally trained model (Note 3) that operates by replicating the 8B model constructed in Phase 1 into eight, each of which is differentiated and linked as an expert model. This model was developed from full scratch, and has achieved the same or better performance as “GPT-3.5 Turbo” in the “Japanese MT-Bench,” an index for evaluating writing and speaking. The name of the model was proposed by team members under the theme of “a name of an animal that sounds Japanese and is familiar to people,” and was decided by a vote.
- Development model public URL
This model is licensed under the Apache License 2.0 and may be freely used for research and commercial purposes.
Tanuki-8x8B: https://huggingface.co/weblab-GENIAC/Tanuki-8x8B-dpo-v1.0
Tanuki-8B: https: //huggingface.co/weblab-GENIAC/Tanuki-8B-dpo-v1.0
- Demo Public URL
A demo of “Tanuki-8B,” a lightweight version of “Tanuki-8x8B,” is available at the following URL. Please access the following URL to try the actual conversation.

Demo screen
<Featuresof“Tanuki-8x8B
Tanuki-8×8B” is trained mainly in writing and dialogues, and the “Japanese MT-Bench,” which measures such abilities, achieved the same performance as GPT-3.5 Turbo as a model that was developed by full scratch from the preliminary training.
- Evaluation onNejumi LLMLeaderboard 3
First, model performance was evaluated using the Nejumi LLM Leaderboard3 benchmark program, the latest (Note 4) benchmark system for evaluating the overall Japanese language capability of large-scale language models, and compared to a set of existing models (Note 5).
Orange represents models developed in this project, blue represents other models
The Nejumi LLM Leaderboard3 is a system that evaluates the performance of language models from various perspectives, including knowledge and safety as well as sentence production and dialogue ability. the overall score of Tanuki-8×8B in this benchmark was 0.57/1.00, which is comparable to OpenAI’s GPT-3.5 Turbo (0.58/1.00) of OpenAI.
The most important aspect of this development was to improve the model’s ability to compose and interact, and the Japanese MT-Bench, which objectively evaluates this ability, gave it a score of about 7 out of 10, which is on the same level as GPT-3.5 Turbo (7 points) and CyberAgentLM3-22B- Chat (7 points) and are on the same level (Note 6).
- Manpower assessment
In addition to measurements on the Nejumi LLM Leaderboard 3, we also evaluated models manually The Nejumi LLM Leaderboard 3 used to evaluate model performance is a fully automated framework that evaluates model output on a variety of topics by scoring them using algorithms and GPT-4. Although it is a measurement method with excellent objectivity and reproducibility, the evaluation does not include human feedback or actual interaction ratings, which can lead to a discrepancy between the benchmark scores and the user’s perception of use.
In this project, with the aim of evaluating the models’ writing and dialogue skills from a more practical perspective, we conducted an additional evaluation based on the same principle as the system widely known as ChatBot Arena, in which users compete in the form of blind tests to determine the superiority of various models’ answers to user questions (evaluation period: August 2024 to August 2024 ). Specifically, we conducted a test in which a human evaluated the superiority or inferiority of the output of two randomly selected language models in response to a user question (evaluation period: August 19-24, 2024). In addition to the development team, members of the Matsuo-Iwasawa Lab’s LLM community participated in the evaluation and collected over 2000 dialogue data (to be released at a later date).
We evaluated and compared the output of 13 different models, including representative high-performance models developed or additionally learned in Japan, as well as commercial LLMs such as GPT-3.5/4, Gemini-1.5, Claude-3.5, etc. The aggregate results showed that the performance of “Tanuki-8×8B” ranked next to GPT4o, Gemini The results show that the performance of “Tanuki-8×8B” is equivalent to GPT4o, Gemini-1.5-pro, and Claude-3.5-sonnet, and is in the same performance range as GPT-4o-mini, Gemini-1.5-flash, and CyberAgentLM3-22B-Chat. A series of evaluations showed that the developed 8x8B model exhibits superior output performance during the practical phase of user interaction.
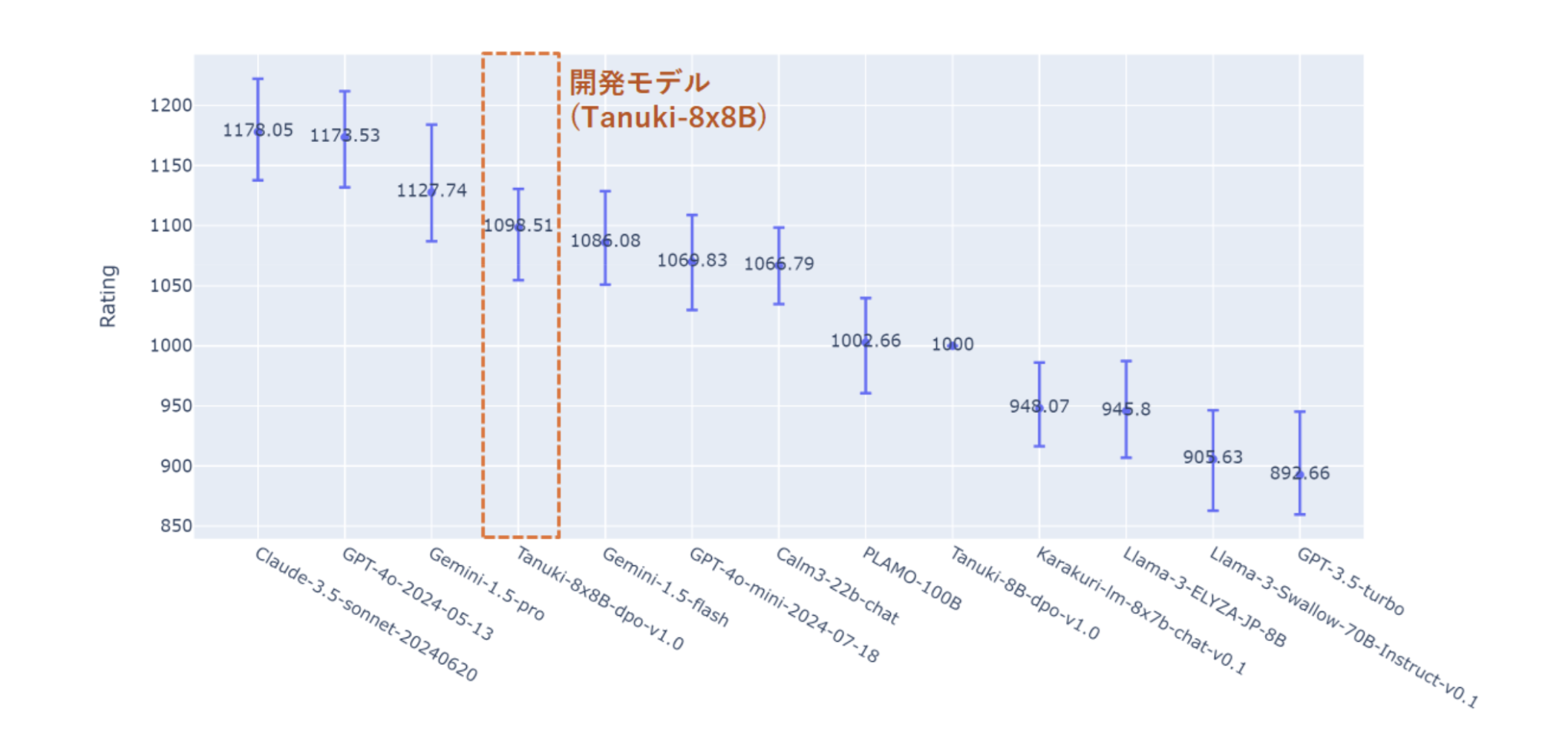
Ratings of model superiority byChatBot Arena’sBradley-Terry model
(Tanuki-8B performance is set to the base value (1000))
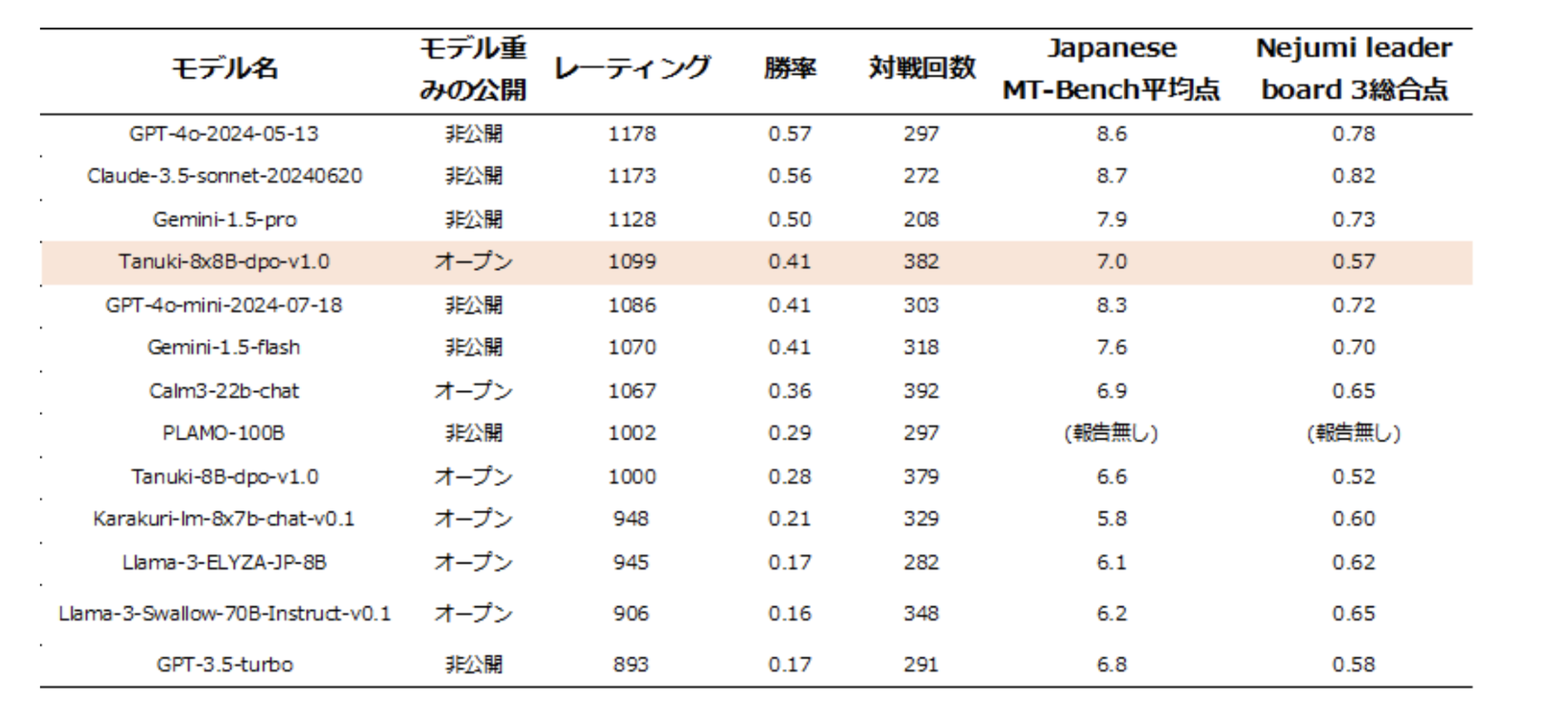
Comparison of model performance
On the other hand, “Tanuki-8×8B” has some advantages over foreign models. Tanuki-8x8B” has different advantages from foreign models: foreign models tend to give rather inorganic and formal responses, whereas the model in question was good at giving empathic and thoughtful responses and composing in a natural way with natural language.



By continuing to develop models based on the open knowledge accumulated through this project, it is expected that a group of LLMs with originality and competitiveness unique to Japan will be born.
0Related information:
The development process and knowledge of this model is openly available on the project page below and in Zenn blog posts. Please see below for more details.
GENIAC Matsuo Lab LLM Development Project Special Page:
https://weblab.t.u-tokyo.ac.jp/geniac_llm/
Zennblog post:
https://zenn.dev/p/matsuolab
annotation
(Note 1) New Energy and Industrial Technology Development Organization (NEDO) “Research and Development Project for Strengthening Post-5G Information and Communication System Infrastructure / Development of Post-5G Information and Communication Systems” project. The Ministry of Economy, Trade and Industry (METI) is leading the “GENIAC” project, which provides support for computational resources necessary for the development of basic models and encourages collaboration among related parties.
For more information on GENIAC, click here:
https://www.meti.go.jp/press/2023/02/20240202003/20240202003.html
https://www.meti.go.jp/policy/mono_info_service/geniac/index.html
(Note 2) Models and codes developed by each team in Phase 1 are also available below.
Model (HuggingFace): https://huggingface.co/weblab-GENIAC
Code (GitHub): https://github.com/matsuolab/nedo_project_code
(Note 3) The architecture called Mixture of Experts (MoE) is realized by a method called upcycling. 47B total parameters, 13B active parameters.
https://arxiv.org/abs/2406.06563
https://arxiv.org/abs/2212.05055
(Note 4) Information as of August 2024.
(Note 5) Performance of developed models was evaluated internally within the project; for performance of existing models, data downloaded on August 13, 2024 from the relevant site was used.
(Note 6) Due to the specifications of the benchmark program, even for the same model, the score fluctuates by 0.1-0.2 points each time it is measured, confirming that the rankings among the models vary.
contact information (for inquiries) (e.g. corporate phone number)
Matsuo-Iwasawa Laboratory, Graduate School of Engineering, The University of Tokyo
E-mail: pr@weblab.t.u-tokyo.ac.jp




