GENIAC 松尾研 LLM開発プロジェクト

本プロジェクトは、大規模言語モデル講座の修了生を含む、松尾・岩澤研究室講座の修了生および一般公募によって集まった有志の開発者(⺠間企業・研究者・学生で構成)約250名が7チームに分かれ、各チーム10BクラスのLLMをコンペティション形式で開発を行い、優勝チームが50BクラスのLLMを作り、これらのモデルやコード開発で得た知見を共有する事を目的に行われます。
国立研究開発法人新エネルギー・産業技術総合開発機構(以下「NEDO」)の「ポスト5G情報通信システム基盤強化研究開発事業/ポスト5G情報通信システムの開発(助成)」に係る公募に採択されており、経済産業省が主導する基盤モデルの開発に必要な計算資源に関する支援や関係者間の連携を促す「GENIAC」プロジェクトの一環として行われます。
GENIACの詳細はこちら:https://www.meti.go.jp/press/2023/02/20240202003/20240202003.html
LLM開発者を増やし、日本からイノベーションを生み出す
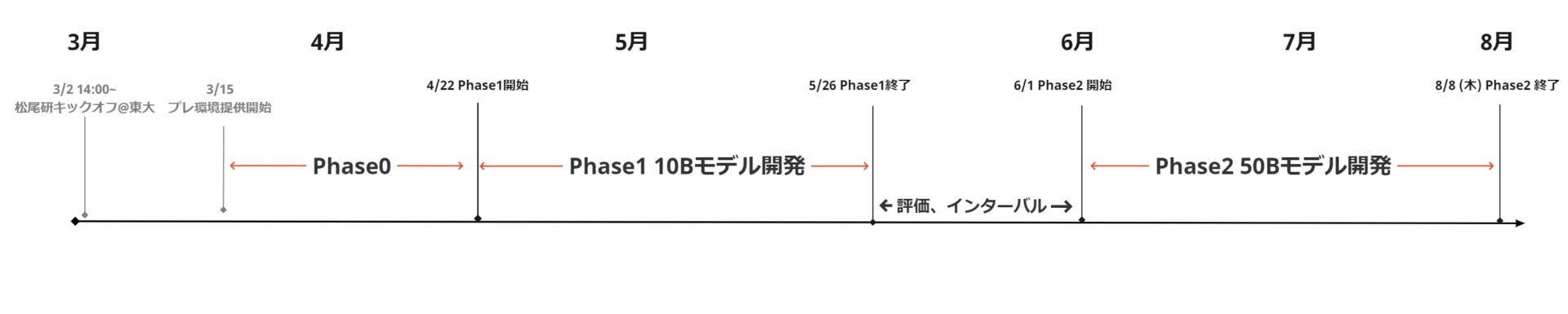
2つのフェーズから構成されており、
Phase1では7チームが10Bクラスのモデルを開発するコンペティションを実施。
Phase2では、Phase1の優勝チームが50Bクラスのモデル開発に挑戦します。

開発チーム紹介
チーム ビジネス
- リーダー:河越淳
- 開発方針:ビジネス利用可能なLLMの開発
チーム Kuma
- リーダー:熊谷壮一郎
- 開発方針:学習の効率化・高速化
チーム たぬき
- リーダー:畠山歓
- 開発方針:良質な日本語データの構築による性能改善
チーム JINIAC
- リーダー:中村仁
- 開発方針:日本語に特化したLLMの開発
チーム 甲(きのえ)
- リーダー:朏島和香那
- 開発方針:日本語出力品質への特化
チーム Zoo
- リーダー:三内顕義
- 開発方針:MoE構造をとるLLMの開発
チーム 天元突破
- リーダー:尾崎大晟
- 開発方針:ハルシネーションを最大限逓減したLLMの開発
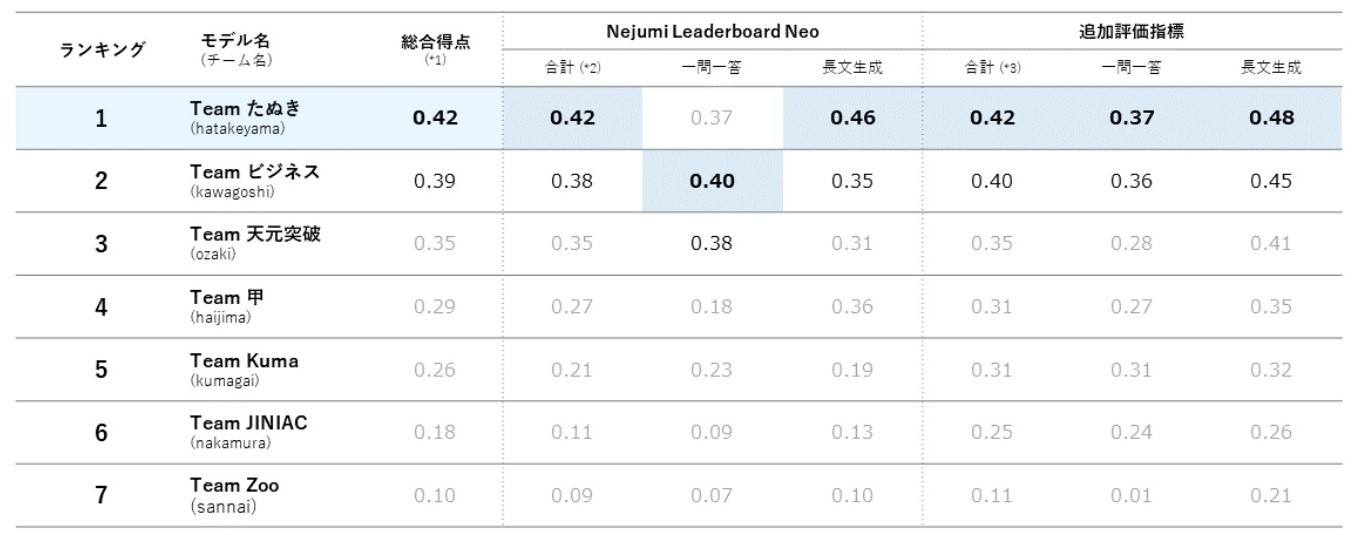
Phase1 コンペティション結果
6/1(土)にPhase1結果発表会が行われました。
全チームハイレベルな結果を達成するなか、「チームたぬき」(リーダー:畠山歓)が優勝し、Phase2への進出を決めました。
8月初めのPhase2終了まで、現在も開発が進行中です。
Phase2 成果物「Tanuki 8×8B」公開
- Phase2にて開発したモデル「Tanuki 8×8B」を公開しました。
- フルスクラッチで開発されており、作文、会話を評価する指標「Japanese MT- Bench」において「GPT-3.5 turbo」と同等以上の性能を達成。
- Apache License2.0のライセンスに基づき、研究および商業目的での自由な利用が可能。
- 「Tanuki 8×8B」の軽量版である、「Tanuki-8B」をチャット形式で利用できるデモも公開。
モデル・デモ公開URL
Tanuki-8x8b:https://huggingface.co/weblab-GENIAC/Tanuki-8x8B-dpo-v1.0
Tanuki-8b:https://huggingface.co/weblab-GENIAC/Tanuki-8B-dpo-v1.0
デモ公開:https://huggingface.co/spaces/weblab-GENIAC/Tanuki-8B-dpo-v1.0
Tanuki特設ページ:https://tanuki-llm.github.io/
プロジェクト成果物 / ノウハウ共有






本プロジェクトのSlackは「松尾研 LLM Community」上で行われ、LLMに関心のある方のためのコミュニティとしてメンバーを受け入れています。
・参加することで期待できる点
- 開発の様子をリアルタイムでモニタリングできる
- 内部で開催されるLLM関連のイベントに参加できる
- 上記を通じてLLMへの理解を深められる