Our paper for Interspeech2018 was accepted.
【Information】
Kei Akuzawa, Yusuke Iwasawa, Yutaka Matsuo: “Expressive Speech Synthesis via Modeling Expressions with Variational Autoencoder”, in Proc. Interspeech 2018.
【Overview】
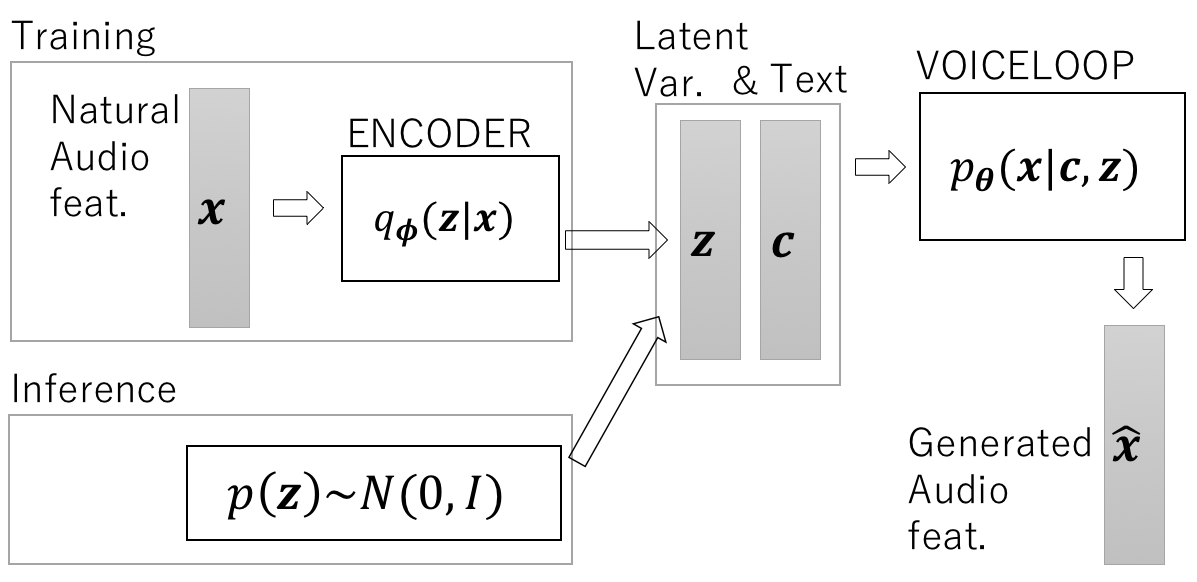
Recent advances in neural autoregressive models have improve the performance of speech synthesis (SS). However, as they lack the ability to model global characteristics of speech (such as speaker individualities or speaking styles), particularly when these characteristics have not been labeled, making neural autoregressive SS systems more expressive is still an open issue. In this paper, we propose to combine VoiceLoop, an autoregressive SS model, with Variational Autoencoder (VAE). This approach, unlike traditional autoregressive SS systems, uses VAE to model the global characteristics explicitly, enabling the expressiveness of the synthesized speech to be controlled in an unsupervised manner.
【Demo】
https://akuzeee.github.io/VAELoopDemo/