
発表のポイント
- 経産省及びNEDOが進める日本国内の生成AI基盤モデル開発を推進する「GENIAC」プロジェクトにおいて、松尾・岩澤研究室が「Tanuki-8×8B」を開発・公開。
- 本モデルは、フルスクラッチで開発されており、対話、作文能力を評価する指標「Japanese MT-Bench」において「GPT-3.5 Turbo」と同等以上の性能を達成。
- Apache License 2.0のライセンスに基づき、研究および商業目的での自由な利用が可能。「Tanuki-8×8B」の軽量版である、「Tanuki-8B」をチャット形式で利用できるデモも公開。
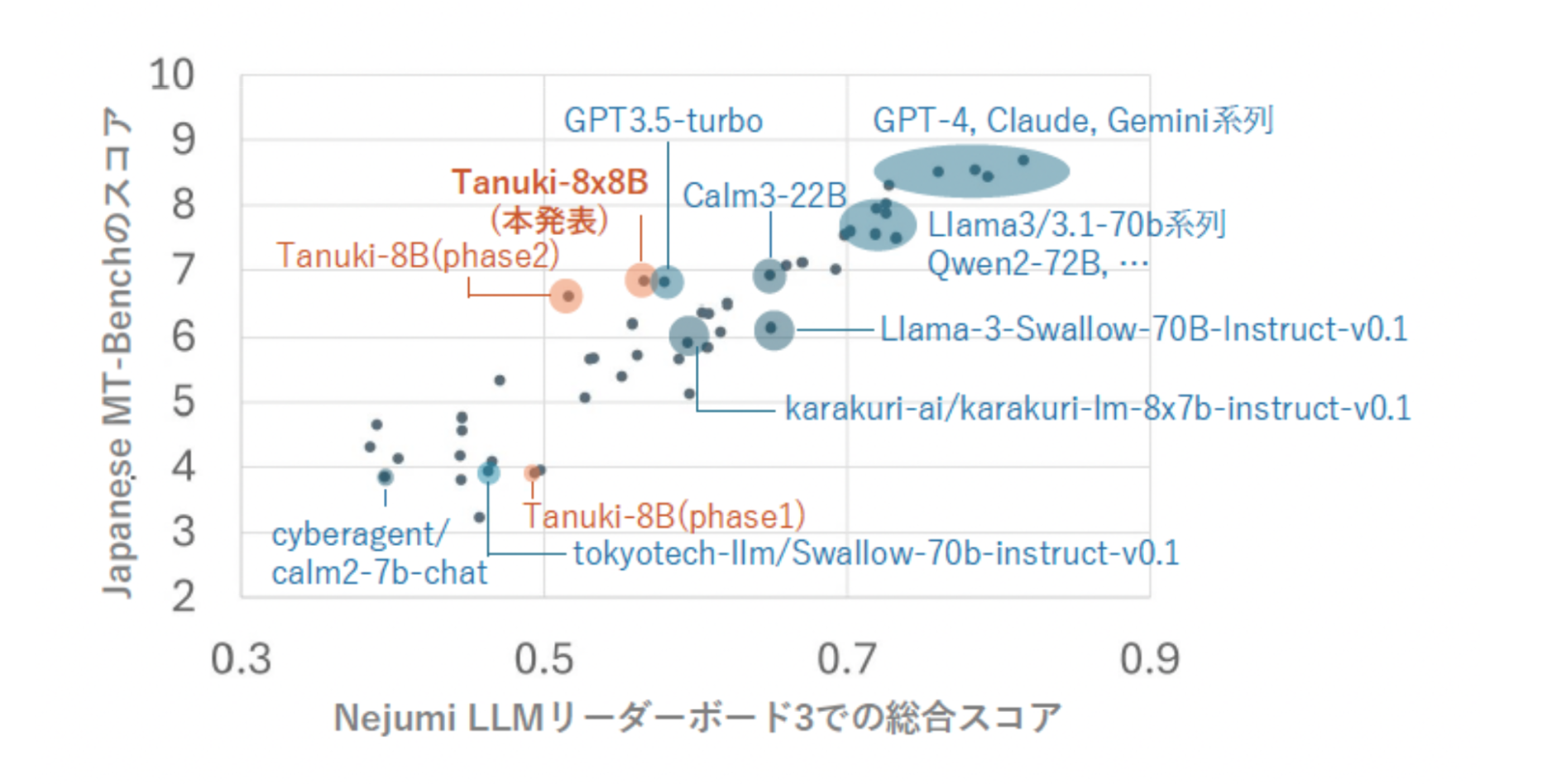
本モデルのNejumi LLMリーダーボード3における評価
発表内容
東京大学大学院工学系研究科技術経営戦略学専攻 松尾・岩澤研究室(以下「松尾研」)は、経済産業省及び国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)が推進する、国内の生成AIの開発力を強化するためのプロジェクト「GENIAC(Generative AI Accelerator Challenge)」(注1)において、大規模言語モデル「Tanuki-8×8B」を開発し、公開いたしました。
〈開発の背景〉
本活動は、日本国内の生成AI基盤モデル開発を推進する「GENIAC」プロジェクトにおいて、2023年8月に公開した100億パラメータサイズのLLM「Weblab-10B」の開発経験をベースに、LLM開発を進めるものです。
松尾研が提供する大規模言語モデル講座(2023年8月開催、2000名以上が受講)の修了生及び一般公募によって集まった有志のメンバー(⺠間企業・研究者・学⽣で構成)が、それぞれの知見を取り入れながら開発に取り組みました。
開発工程は2つのフェーズに分かれており、Phase1(注2)では7チームに分かれてコンペティション形式で開発を進め、Phase2ではPhase1の優勝チームが更に大規模なモデル開発に挑戦しました。「Tanuki-8×8B」は本取り組みの結果開発され、公開するものです。
松尾研GENIACプロジェクトについては下記をご覧ください。
https://weblab.t.u-tokyo.ac.jp/geniac_llm/
〈「Tanuki-8×8B」の概要〉
「Tanuki-8×8B」はPhase1で構築された8Bモデルを8つに複製し、それぞれを専門家モデルとして分化・連携させることで動作するように効率的に追加学習されたモデル(注3)です。本モデルは、フルスクラッチで開発されており、作文、会話を評価する指標「Japanese MT-Bench」においては「GPT-3.5 Turbo」と同等以上の性能を達成しています。モデル名は「日本らしく、親しみを覚える動物の名前」というテーマでチームメンバーで案を出し、投票で決定しました。
- 開発モデル公開URL
本モデルはApache License 2.0のライセンスに基づき、研究および商業目的での自由な利用が可能です。
Tanuki-8x8B:https://huggingface.co/weblab-GENIAC/Tanuki-8x8B-dpo-v1.0
Tanuki-8B:https://huggingface.co/weblab-GENIAC/Tanuki-8B-dpo-v1.0
- デモ公開URL
「Tanuki-8×8B」の軽量版である、「Tanuki-8B」をチャット形式で利用できるデモを下記URLで公開しております。下記URLにアクセスし実際の会話をお試しください。

デモ画面
〈「Tanuki-8×8B」の特徴〉
「Tanuki-8×8B」は文章の作文や対話を中心に学習しており、当該能力を測る「Japanese MT-Bench」では事前学習からフルスクラッチで開発を行ったモデルとして、GPT-3.5 Turboと同等の性能を達成しています。
- Nejumi LLMリーダーボード3における評価
はじめに、大規模言語モデルの総合的な日本語能力を評価するための最新(注4)のベンチマークシステムであるNejumi LLMリーダーボード3のベンチマークプログラムを用いてモデル性能を評価し、既存のモデル群(注5)と比較しました。
橙色が本プロジェクトで開発されたモデル、青色が他モデルを表す
Nejumi LLMリーダーボード3は言語モデルの文章作成、対話能力のほか、知識や安全性など、さまざまな観点から性能を評価するシステムです。本ベンチマークにおける「Tanuki-8×8B」の総合スコアは0.57/1.00で、OpenAIのGPT-3.5 Turbo(0.58/1.00)と同程度の性能であることが分かりました。
今回の開発で最も力を入れた点は、モデルの作文・対話能力の向上です。この能力を客観的に評価するJapanese MT-Benchでは、10点満点中7点程度のスコアが得られました。この成績は、GPT-3.5 Turbo(7点)やCyberAgentLM3-22B-Chat(7点)と同水準(注6)です。
- 人手での評価
Nejumi LLMリーダーボード3での計測に加えて、人手でのモデル評価を行いました。モデルの性能評価に用いたNejumi LLMリーダーボード3は、さまざまなトピックに関するモデルの出力を、アルゴリズムやGPT-4を用いた採点によって全自動で評価する枠組みです。客観性や再現性に優れた計測手法ではありますが、評価には人間のフィードバックや実際の対話評価が含まれないため、ベンチマークスコアとユーザーの使用感には乖離が生じる可能性があります。
そこで本プロジェクトでは、より実践的な観点からモデルの作文・対話能力を評価することを目的として、ユーザーの質問に対する種々のモデルの回答の優劣をブラインドテストの形で競わせる、いわゆるChatBot Arenaとして広く知られるシステムと同じ原理で追加評価を実施しました。具体的には、ユーザーの質問に対し、ランダムに選ばれた2つの言語モデルの出力の優劣を、人間が評価する試験を実施しました(評価期間:2024年8月19〜24日)。開発チームに加え、松尾・岩澤研のLLMコミュニティに参加するメンバーが評価に参加し、2000件以上の対話データを収集しました(後日公開予定)。
国内で開発、あるいは追加学習された代表的な高性能モデルに加え、GPT-3.5/4、Gemini-1.5、Claude-3.5などの商用LLMを含めた13種類のモデルの出力を比較評価しました。集計の結果、「Tanuki-8×8B」の性能はGPT4o、Gemini-1.5-pro、Claude-3.5-sonnetに次ぐ順位に相当することが分かりました。GPT-4o-mini、Gemini-1.5-flash、CyberAgentLM3-22B-Chatと同レベルの性能帯に位置しています。一連の評価より、ユーザーとの対話を想定した実践的なフェーズにおいて、開発した8x8Bモデルが優れた出力性能を示すことが分かりました。
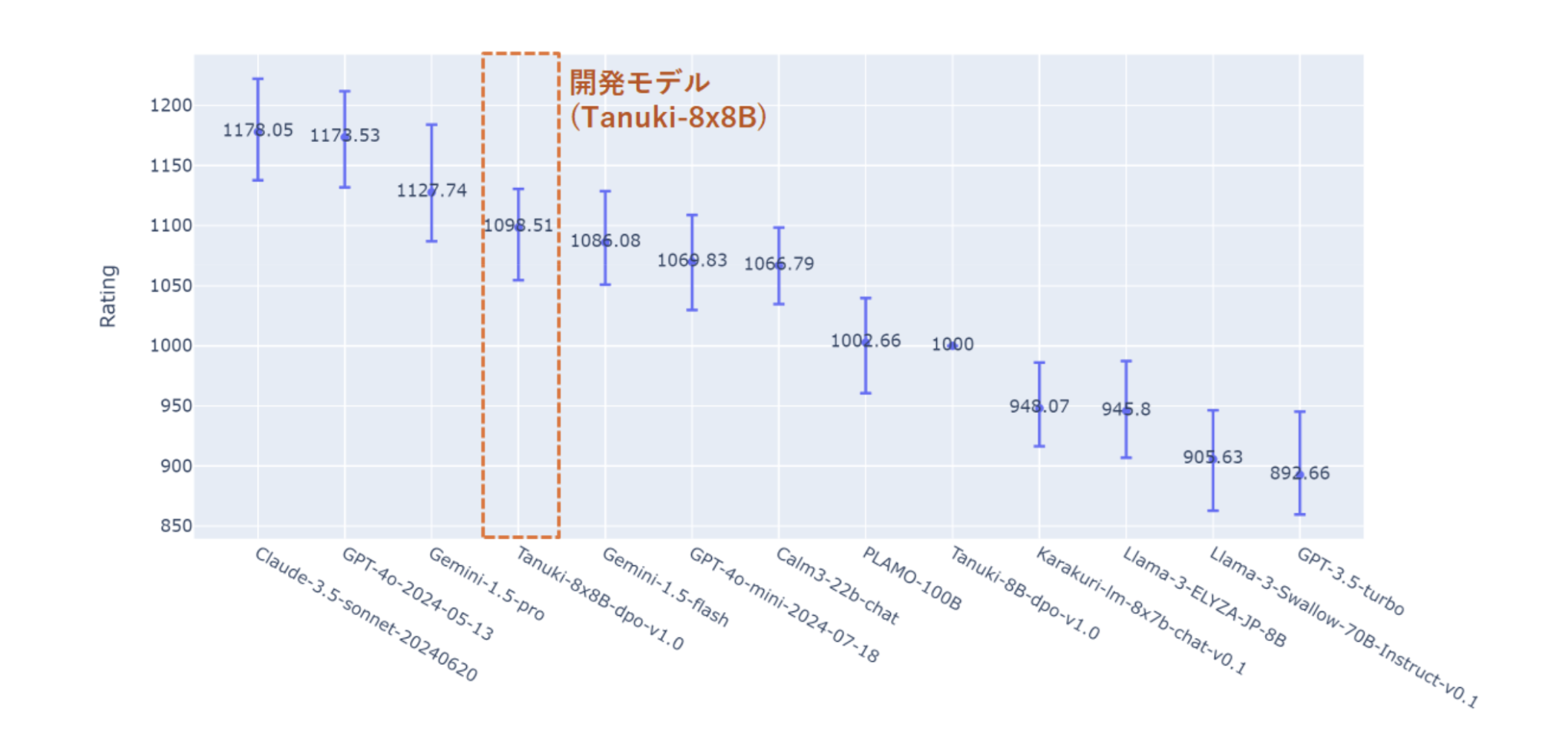
ChatBot ArenaのBradley-Terry modelによってモデルの優劣をレーティングした結果
(Tanuki-8Bの性能を基準値(1000)に設定)
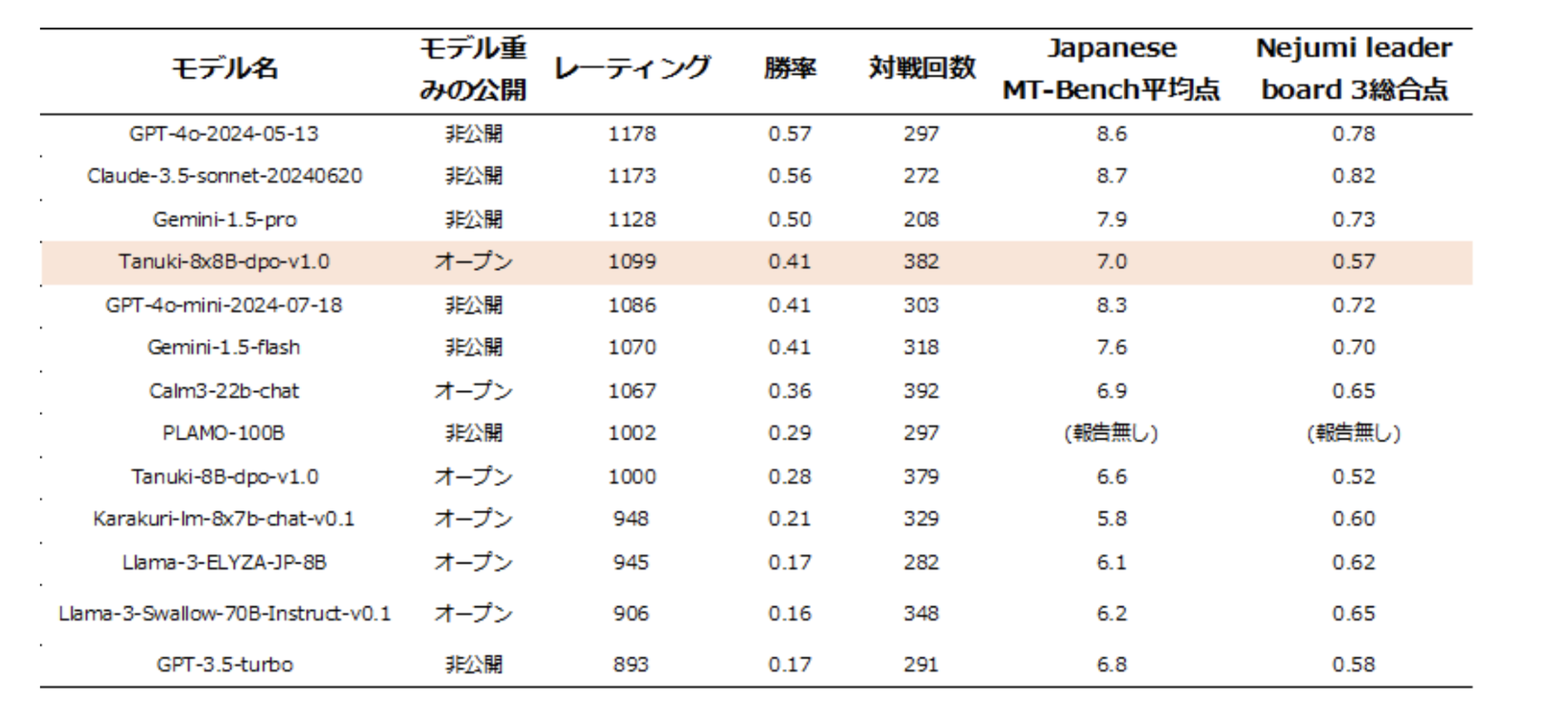
モデルの諸性能の比較
本モデルに残された課題として、Japanese MT-Benchの結果も含めた総合的な推論性能はGPT-4o、Gemini-1.5-pro、Claude-3.5-sonnetなどの海外の最先端モデルにはまだ追いついていない点などが挙げられます。一方で「Tanuki-8×8B」は、海外モデルとは異なる長所を持つことも明らかになりつつあります。海外モデルはどちらかというと無機質で形式的な返答をする傾向にありますが、それとは対照的に、当該モデルは共感性や思いやりのある返答や、自然な言葉遣いでの作文が得意でした。



今回のプロジェクトを通して集積したオープンな知見をもとにモデル開発を継続して行うことで、日本ならではのオリジナリティや競争力を兼ね備えたLLM群が誕生することが期待されます。
〇関連情報:
本モデルの開発過程やナレッジは、下記プロジェクトページやZennブログ記事にてオープンに公開されております。詳細は下記をご覧ください。
GENIAC 松尾研LLM開発プロジェクト特設ページ:
https://weblab.t.u-tokyo.ac.jp/geniac_llm/
Zennブログ記事:
https://zenn.dev/p/matsuolab
注釈
(注1)国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)「ポスト5G情報通信システム基盤強化研究開発事業/ポスト5G情報通信システムの開発」事業。経済産業省が主導する基盤モデルの開発に必要な計算資源に関する支援や関係者間の連携を促す「GENIAC」プロジェクトの一環として採択事業者に一定の計算資源に関わる助成を行うもの。
GENIACの詳細はこちら:
https://www.meti.go.jp/press/2023/02/20240202003/20240202003.html
https://www.meti.go.jp/policy/mono_info_service/geniac/index.html
(注2)Phase1で各チームが開発したモデル、コードも併せて下記にて公開。
モデル(HuggingFace):https://huggingface.co/weblab-GENIAC
コード(GitHub):https://github.com/matsuolab/nedo_project_code
(注3)Mixture of Experts(MoE)と呼ばれるアーキテクチャを、アップサイクリングと呼ばれる手法で実現。総パラメータは数47B、アクティブパラメータ数は13B。アップサイクリングについての参考論文は下記。
https://arxiv.org/abs/2406.06563
https://arxiv.org/abs/2212.05055
(注4)2024年8月時点での情報。
(注5)開発モデルの性能はプロジェクト内部で評価。既存モデルの性能については、当該サイトから2024年8月13日にダウンロードしたデータを使用。
(注6)ベンチマークプログラムの仕様上、同一のモデルであっても、測定のたびに0.1-0.2点程度のスコア変動が生じるため、モデル間の順位が変動することを確認しています。
問合せ先
東京大学大学院工学系研究科 松尾・岩澤研究室 広報担当
E-mail:pr@weblab.t.u-tokyo.ac.jp







