
松尾・岩澤研究室では,「知能を創る」というミッションのもと、世界モデルをはじめとした深層学習やそれを超える基礎技術の開発、ロボティクスや大規模言語モデル、アルゴリズムの社会実証といった幅広い研究領域で活動しています。
こうした活動を更に拡大するため、リサーチインターンシップを開催し、15名の方にご参加いただきました。
▼リサーチインターンシップ概要
https://weblab.t.u-tokyo.ac.jp/news/20240417/
▼インターンテーマ/メンターの紹介記事
https://weblab.t.u-tokyo.ac.jp/news/20240426/
本記事では、リサーチインターンに参加いただいたメンバーの体験記をご紹介します。
- 自己紹介/self-introduction
- 東京大学大学院情報理工学系研究科コンピュータ科学専攻M1の木澤翔太と申します。普段は大規模ニューラルネットワークの解釈性について研究しています。特に、学習ダイナミクスや軽量化に焦点を当てています。これらの研究の関連研究を調べている際に、松尾研究室に所属する研究員の方、学生の方の研究を目にすることがあり、ホームページを見て本インターンへの応募を決意しました。
- 研究内容/About research
- 本インターンでは、「強い宝くじ仮説に関する研究」というテーマに基づき、Dynamic Sparse Training という手法を重みの相互依存性観点から分析しました。
- 強い宝くじ仮説 [1] とは、ランダムに初期化された十分にパラメータ数の多いネットワークの中に、学習後に高い汎化性能を示す疎なサブネットワークが存在するという仮説です。疎なネットワークのマスクと初期値のペアを強い宝くじと呼んでいます。この仮説は、初期化時に汎化性能の高いサブネットワークが存在しているということを示しており、ネットワークの学習前または学習中に重みの刈り込みを行うことで効率的に学習が進められることを示唆しています。
- ネットワークの学習前または学習中に重みの刈り込みを行う手法を Pruning at Initialization (PaI) [2] と呼びます。この PaI は、(1) ニューラルネットワークの重みのマスクのみを更新する sparse selection、(2) マスクは固定し、重みのみを更新する static sparse training、(3) 重みとマスクの両方を更新する dynamic sparse training (DST) に分類されます。
- 厳密に強い宝くじを見つける手法は static sparse training のみですが、マスクだけでなく重みも更新でき自由度の高い DST は、他のプルーニング手法や確率的勾配降下法 (SGD) などの一般的な重みに対する連続最適化手法と比較しても優れた汎化性能を示し [3]、有用な手法です。一方で、DSTの理論的基盤はまだ不明瞭です。特に、DST はどの程度損失を改善できるのか?という疑問はまだ解消されていません。そこで我々はこの疑問に答えるべく、DST を重みの相互依存性の観点から分析し、どの程度損失を改善できるのかを分析しました。なお、重みの相互依存性とは、重みの刈り込みや復元が相互に影響を及ぼす関係を指します。具体的には、ある重みを刈り込むときに、その重みと良い依存関係を持っている重みを同時に削除または復元することで、損失をより効率よく減らすことができるということです。
- 本研究では、RigL [3] というDSTフレームワークを使いました。RigL は、下図に示した通り、まず初期化時にどの程度重みを非活性にするか (刈り込むか) を決めてそれに基づいて初期化を行い、通常の勾配法による重み更新をしつつ、定期的に重みのマスクを交換するというものです。
- 我々は、このマスク交換後の損失関数をテイラー展開し、マスク交換前後の損失の変化量を定式化しました。1次のテイラー展開をすると損失の変化量は以下のように表せます。


ただし、w_t は重み、m_t は w_t に対応するマスク、 Δm_t が交換前後のマスクの差分です。また、マスクは0か1の離散値であるため微分可能ではないですが、ここではstraight-through estimator (STE) を使って微分を計算するものとします。2次のテイラー展開をすると損失の変化量は以下のように表せます。
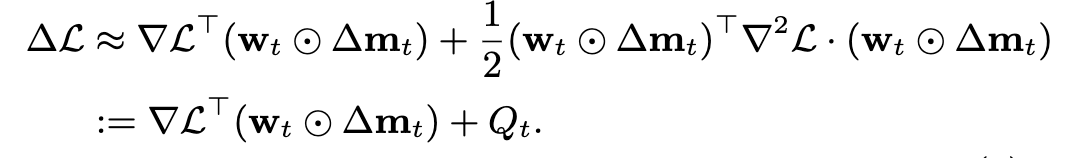
この Q_t が重みの相互依存性となります。これら2つの式を最小化するようなマスク交換を考えることになります。1次の方は、活性な重みにおける勾配と重みの要素積の上位いくつかのマスクを刈り込み、非活性な重みにおける勾配と重みの下位いくつかのマスクを復元させれば最小化が可能です。2次の方は、Q_t の計算量が大きいですが、Hessian vector products [4] の形であるため1回の追加のbackpropのみで計算が可能です。Q_t が計算できれば、最初に刈り込むマスクを決め、その後復元するマスクを決めればヒューリスティックではありますが最小化が可能となります。
実験の結果、重みの相互依存性を加味して最小化することでより効率的に損失を改善できることが示されました。特に1ステップでのマスク交換数が少ない場合、重みの相互依存性の影響は小さいですが、マスク交換数が多くなるにつれてその影響が大きくなることが確認できました。
- 最後に/Closing
松尾研は社会実装がメインの組織だと思われがちですが、基礎研究のレベルも非常に高いです。特に優秀な研究員の方々、学生の方々が多く在籍しており、情報共有や議論も活発に行われています。AI関連では日本トップクラスの研究組織と言えるでしょう。
インターンの期間は、セットアップなどもスムーズにでき、集中して自由に研究にのめり込むことができました。プロジェクトによって進め方は様々ですが、私の場合は集中して作業をしたいタイプだったのもあり、基本テキストで進捗を報告し、週一回メンターの岩澤先生と、同じテーマで研究をしている方数名と打ち合わせをする、というスタイルで研究を進めました。
最後になりますが、メンターの岩澤先生には、本プロジェクトを通じて丁寧に指導していただき大変お世話になりました。また、このような機会を提供していただいた松尾研究室の皆様方には深く感謝しております。ありがとうございました。
References:
[1] Vivek Ramanujan, Mitchell Wortsman, Aniruddha Kembhavi, Ali Farhadi, and Mohammad Rastegari. What’s hidden in a randomly weighted neural network? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
[2] Huan Wang, Can Qin, Yue Bai, Yulun Zhang, and Yun Fu. Recent advances on neural network pruning at initialization. In Lud De Raedt, editor, Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI-22, pages 5638–5645. International Joint Conferences on Artificial Intelligence Organization, 7 2022. Survey Track.
[3] Utku Evci, Trevor Gale, Jacob Menick, Pablo Samuel Castro, and Erich Elsen. Rigging the lottery: Making all tickets winners. In Hal Daum´e III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 2943–2952. PMLR, 13–18 Jul 2020.
[4] Mathieu Dagr´eou, Pierre Ablin, Samuel Vaiter, and Thomas Moreau. How to compute hessian-vector products? In ICLR Blogposts 2024, 2024. https://iclr- blogposts.github.io/2024/blog/bench-hvp/.
いかがでしたでしょうか?
松尾研では研究員を積極的に募集しております。気になる方は下記をご覧ください!
https://weblab.t.u-tokyo.ac.jp/joinus/career/
